SCALE FROM ZERO TO MILLIONS OF USERS — Part 1
Let’s design a systems which supports millions of users.
Before drive into deep let me know you, why you need this. Think you have a website and it’s working file with small amount of users. But day by day users are increasing and website response are getting slow, right? And maybe when your users reach millions your website stuck. It’s just loading and loading. So to prevent this problem we are going to scale/design our system.
Single server setup
At the very beginning we have a single server setup. like app, database, cache, etc. all running form one single server like the image below.

Database
In the first step of scaling we move our database to different server like the image below.

Which databases to use?
Simply you can use SQL or NoSQL it’s up to you. But most of the developers like SQL database because it is a relational database and has been using in software development for last 40 years. But now a days NoSQL getting popular too. MySQL, Oracle database, PostgreSQL are popular SQL database and CouchDB, Neo4j, Cassandra, HBase, Amazon DynamoDB are popular NoSQL database. NoSQL is best for super-low latency, unstructured data and massive amount of data.
Vertical scaling vs horizontal scaling
Vertical scaling, referred to as “scale up”, means the process of adding more power (CPU, RAM, etc.) to your servers. Horizontal scaling, referred to as “scale-out”, allows you to scale by adding more servers into your pool of resources.
You can see vertical scaling has some limitation like and horizontal scaling is more desire for developers.
if many users access the web server simultaneously and it reaches the web server’s load limit, users generally experience slower response or fail to connect to the server. A load balancer is the best technique to address these problems.
Load balancer
A load balancer evenly distributes incoming traffic among web servers that are defined in a load-balanced set like the image below.

Considerations for using load balancer
1.Incase server1 get down load balancer sent all the traffic to server2.
2. if users increasing you can add more server to balance.
The current design has one database, so it does not support failover and redundancy. Database replication is a common technique to address those problems. Let us take a look.
Database replication
a master/slave relationship between the original (master) and the copies (slaves)” means we have a master database and some copy of that maser database. Master database only for handle data insert update & delete operations and slaves/copies database will be used for only data reading like the image below.
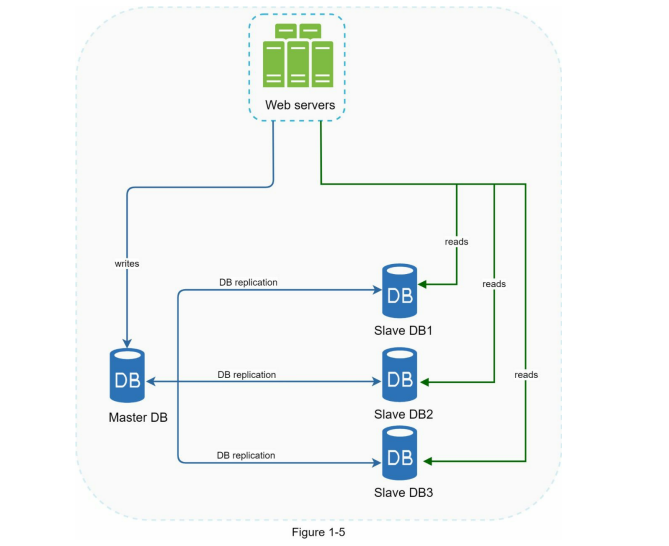
Advantages of database replication
1. Better performance: As read & write operations are in different database.
2. Reliability: If one database destroy for natural disaster we have our backup database.
3. High availability: Now database are in different locations so if one database goes offline use get data from other database.
Considerations of database replication
1. If one slave database goes offline we can get data form others and add new one to cover that offline one.
2. If master database goes offline then we can make a master database form one of slave database. and add more slave database if we need.

Now it is time to improve the load/response time
Cache
When use access to website it sent multiple request to database serve and application performance is greatly affected by calling the database repeatedly. To prevent this problem cashing is best.
Cache is a temporary storage area that stores the result of expensive responses or frequently accessed data in memory so that subsequent requests are served more quickly like the image below.

Considerations of using cache
1. Expiration policy: Caching data expiration time should not be too short so that data call increase gradually and not too long so that updated data will missing.
2. Consistency: Cache data should sync continually.
3. Mitigating failures: “A single point of failure (SPOF) is a part of a system that, if it fails, will stop the entire system from working”, So multiple cache server is recommended.
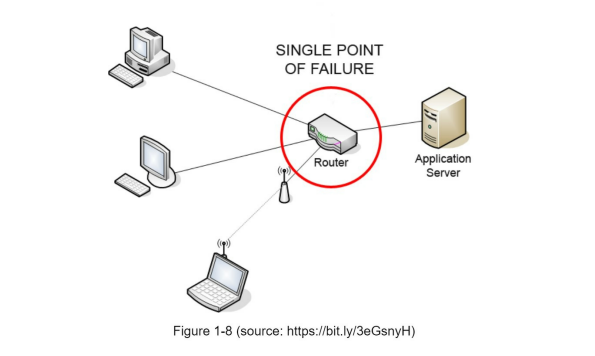
4. Eviction Policy: Once the cache is full, any requests to add items to the cache might cause existing items to be removed. This is called cache eviction. Least-recently-used (LRU) is the most popular cache eviction policy.
Content delivery network (CDN)
CDN is a network of geographically dispersed servers. You can server your static data like(CSS, JS, Images, Videos) from CDN. It make website more faster.
Here is how CDN works at the high-level: when a user visits a website, a CDN server closest to the user will deliver static content. Intuitively, the further users are from CDN servers, the slower the website loads. For example, if CDN servers are in San Francisco, users in Los Angeles will get content faster than users in Europe like the image below.
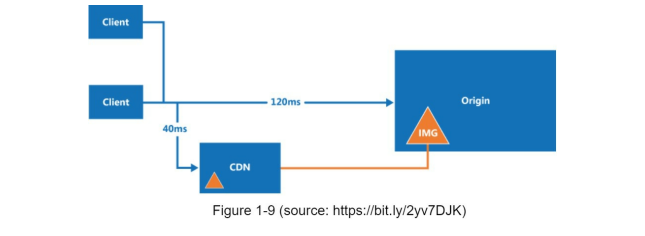
CDN workflow kind of similar to caching, like the image below.
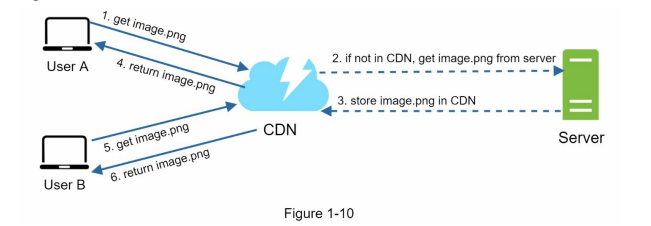
Considerations of using a CDN
1. Cost: As CDN provides from 3rd party and is has costing as per user.
2. Setting an appropriate cache expiry: This is similar to cache expiry policy.
3. CDN fallback: This is similar to SPOF.
Good job! You make a good progress, now sum-up so far we learn. Look the image below.
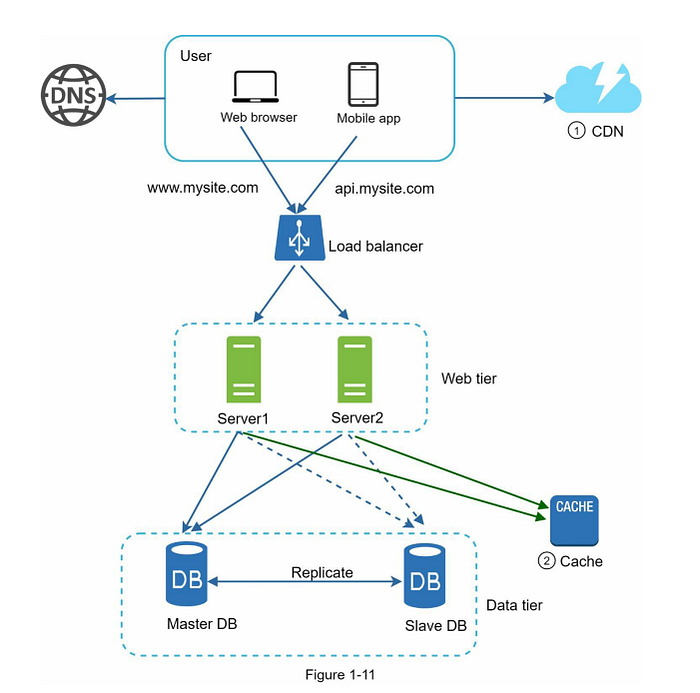
So far we are half way of our great system design to handle millions of users. In this point I'm thinking to write a 2nd part of it as it’s already much longer.
Part 2 link:
Note: All I know about this system design from this great book - “System Design Interview An Insider’s Guide by Alex Xu” and all image credit goes to this books too.
You can read from here:
Feel free to leave a comment if you have any feedback, questions or want me to write about something you interested.
